C++面向对象 - 继承和多态
继承的概念要从代码重用(Reuse)讲起。C++中的重用有四种基本形态:函数、继承、组合、重载,函数是重用的基本形态,而继承和组合则是重用的另一种形态。多态与继承存在着密切联系,C++中的多态由虚函数实现。
基本概念
组合(Composition)
组合的概念十分简单,即一个类包含另一个类的对象作为其数据成员。实际上当我们定义类的数据成员时,就是将class定义的类型与数据成员的类型组合起来;只不过这里组合的是C++的基本类型,而用户自定义的类型当然也允许这样的组合。
1 | class A { |
在组合类中访问成员对象的方式与普通数据成员别无二致。当实例化B类的对象时,编译器同时会调用A类的构造函数,创建a的成员实例。
继承(Inheritance)
相比于组合,继承关系显然更为常见。具有继承关系的两个类中,子类/派生类可以获得父类/基类中的几乎所有数据成员和函数成员,同时子类还可以在此基础上定义新的成员。
1 | class A { //父类或基类 |
注意到在冒号后还有一个访问限定符public,这实际上意味着C++中的继承有三类形式,主要区别在于基类中各个成员的访问权限在派生类中是否会发生变化:
- public继承:基类的public和protected成员也会对应称为派生类中的public和protected成员,基类的private成员则无法被派生类直接访问;
- protected继承:基类的public和protected成员都会成为派生类中的protected成员;
- private继承【默认值】:基类的public和protected成员都会成为派生类中的private成员;
最为常用的是public继承,但它并非默认值,所以应当显式地指明继承方式。
另外,C++中也支持多重继承,形式为class C : public A, public B, ... {...},不过需要注意多重继承不能造成接口的冲突。继承方式和多重继承是C++的继承区别于Java继承的两个明显特点。
继承的行为特征
构造、析构和初始化列表
-
以下成员函数不会被派生类继承:
- 基类的构造函数、拷贝构造函数和析构函数
- 基类的友元函数
- 基类的重载运算符
-
但是,如果基类的构造函数是默认的,那么编译器在创建派生类对象时将会自动调用基类的默认构造函数而无需显式指明,这与组合的行为一致,也是与Java和Python明显不同的一点。然而当自定义构造函数时,根据上面的规则,这个函数无法被子类继承,因此子类需要通过其它方式初始化来自父类的成员——这就是初始化列表。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20class Base { //基类
protected:
int x;
public:
Base(int a);
...
}
Base::Base(int a) { //基类的构造函数
this->x = a;
}
class Derived : public Base { //派生类
int y;
public:
Derived(int b);
...
}
Derived::Derived(int a1, int b) : Base(a1), y(b) {
//派生类的初始化列表,除了构造父类还初始化了成员变量
...
}- 初始化列表不仅可以用于父类构造,也可以用于组合类对象成员的构造,还可以用于初始化类的数据成员
- 初始化const成员变量和引用变量必须使用初始化列表(C++11开始也可在类定义时初始化)
- 实际执行时初始化的顺序与初始化列表中书写的顺序无关。构造函数的调用严格按照继承关系;普通变量按照在类定义中声明的顺序一次初始化。
- 还可以在定义普通变量的时候使用类似的形式:
int j(10);
-
构造函数的调用流程:总体原则是先父类,后子类,默认无参数
- 子类是否自定义构造函数?
- 【否】先调用父类无参数的默认或自定义构造函数,再调用子类的默认构造函数
- 如果父类没有满足条件的构造函数,则报错
- 【是】子类是否显式调用父类的构造函数?
- 【是】按照初始化列表的规定先调用父类构造,再调用子类构造
- 【否】先先调用父类无参数的默认或自定义构造函数,再调用子类的自定义构造函数
- 如果父类没有满足条件的构造函数,则报错
- 【否】先调用父类无参数的默认或自定义构造函数,再调用子类的默认构造函数
- 子类是否自定义构造函数?
-
析构函数的调用流程:先子类,后父类,与继承顺序相反,不需要显式指出,编译器完全代劳
同名遮蔽 / 重定义(Redefination)
- 当派生类中定义了与基类同名的成员变量或成员函数,调用这些成员只会定向至派生类成员
- 基类和派生类的同名成员函数不构成重载关系,只要同名,无论参数列表是否相同,都会以派生类的成员为准
- 可以通过
Base::func()的形式在派生类中调用基类的同名函数
向上类型转换(Upcasting)
Upcasting的含义来源于:派生类对象从根本上来讲也是基类的对象。
- Upcasting在C++中是默认行为,同时也是安全的。当把派生类对象赋给基类对象的变量 / 指针 / 引用时,编译器将把它视为基类对象,使用基类类型的变量 / 指针 / 引用不会访问到派生类中独有的成员;
- 对于同名的成员变量或者重写的子类方法,Upcasting也会忽略。
- 与Upcasting相对的概念是Downcasting,也就是将基类对象赋给派生类的变量 / 指针 / 引用。Downcasting是不安全的(因为派生类的定义中可能包含基类未实现的方法),程序员要三思而后行
多态
- 多态(Polymorphism)是指有类型语言中特定接口根据调用者类型的不同表现出不同的行为。
- 无继承,不多态
- 关于多态的具体形式,看以下这段代码:
1 | class Shape { |
这段代码想要实现的是使用Shape类的一个指针,根据子类的不同使得求面积的方式发生变化。这里利用到了Upcasting,然而根据上文提到它的特征,无论赋给的是哪个子类的地址,shape调用的area函数正常情况下都是基类Shape的版本。
-
以上特性被称为静态链接,或早绑定(early binding)。简单来讲,编译器在程序运行前就将Shape类和其定义中的area方法链接了起来,表现到代码的行为上,就是执行哪个方法要看指针/引用的类型,而非内容。
-
而我们要实现的功能则是根据指针实际指向的内容决定调用哪个版本的方法,这是要求实现动态链接,或称为动态绑定(Dynamic Binding)。这也是多态的基本形式。
-
C++中,多态是通过虚函数来实现的。
虚函数
-
虚函数的形式:在基类的方法之前加上一个关键字
virtual,这样,派生类中重新定义基类中定义的虚函数时,会告诉编译器不要静态链接到该函数,而是在运行时进行链接。 -
如果基类的某个函数成员被声明为虚函数,那么重写的子类同名函数无论是否加
virtual关键字都将成为虚函数,因此推荐也加上 (hhh -
虚函数或者说动态链接的实现是依靠虚函数表和虚函数指针。
- 从存储空间上来讲,正常情况下,一个类在内存中所占的空间仅包括其成员变量,而成员函数则是在代码段中存放,编译器在编译和链接阶段会把类的函数成员做静态链接;既然我们先在是动态链接,那么就需要在内存中占用一定的空间存放函数的地址(表),并使用指针指向这些地址。
虚函数表的运行机制
-
每个存在虚函数的类都在内存中有一张虚函数表;每个这些类的对象都有一个虚函数指针作为隐藏成员。
-
每个虚函数表中按照声明顺序依次存放各个虚函数的指针,包括从基类中继承的虚函数;
-
如果派生类的虚函数没有重写基类,那么将按顺序存放在虚函数表的后面;
-
如果重写发生了,那么在派生类的虚函数表中,这个函数的地址将会覆盖原有基类同名函数的地址。这样一来,当使用基类指针调用该函数时,虚函数指针指向的就是重写后函数的地址;
-
多重继承的情况下,每个父类都有一张独立的虚函数表,也就是类似于高维数组的形式;子类的方法重写会覆盖各个父类中所有重名函数的地址。
-
需要注意的是,虚函数表中的地址与函数成员实际的访问权限无关,非public的函数成员也会出现在其中,因此也存在潜在的安全隐患。
纯虚函数和抽象类
- 纯虚函数:基类的虚函数体中给不出任何实现。定义方式为
virtual int func() = 0 - 抽象类:至少含有一个纯虚函数的类被称为抽象类。
- 抽象类不允许直接实例化
- 子类必须重写纯虚函数才能正常使用;没有重写全部纯虚函数的子类同样成为抽象类
- 抽象类也支持多重继承,这是与Java的一个显著不同
模板和STL
模板(Template)也是C++中实现代码重用的一种机制。它专门用于处理数据类型不同,但其它行为一致时的代码重用问题,是一种对类型进行参数化的工具。C++的模板分为两类。
- 函数模板。基本形式如下:函数定义中尖括号内的被成为模板形参,一般会使用
1
2
3
4
5
6
7
8template <Typename T1> void swap(T1& a, T1& b) {
...
}
...
int main(void) {
int x=1, y=2;
swap(x, y); //调用时无需指明类型,会自动识别;
}Typename或class关键字+标识符的形式,两个关键字是等效的,没有区别。 - 类模板。基本形式如下:需要注意的是成员函数的类外定义和实例化的方式,与函数模板存在一些不同。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18template <class T1, class T2> class Test {
T1 t1;
T2 t2;
public:
T1 func(T2 x);
}
...
template<class T1,class T2>
T1 Test<T1,T2>::func(T2 x){
...
//类外定义成员函数的签名可以说相当复杂
//为了可读性往往分为两行,不影响定义的有效性
}
...
int main(void) {
Test<char, int> t0; //实例化对象时显式指定类型
t0.func(3);
}
模板的声明或定义只能在全局,命名空间或类范围内进行。即不能在局部范围如函数内进行。
C++不是一个跨平台的语言,但它还是提供了一套标准模板类(Standard Template Library,简称STL),这些模板类多为常用的数据结构,在各个平台上表现出一致的行为,因此广泛地被使用。关于STL的具体信息,请见本站的另一篇博文:C++ STL常用方法归纳 | Sumsky’s Blog
异常处理
Throw-Try-Catch基本概念
参考文献:
异常处理用于使程序员提前预见到程序中因为用户输入等可能导致的异常情况并针对性地加以处理;基本的形式是通过throw生成中断,通过try-catch块来实现捕获和后续处理。
例如对于除法程序中除数为零导致的异常处理机制:
1 | int divide(int a, int b) { |
使用throw-try-catch进行异常处理的流程是:
- 异常被throw抛出后,如果其位于某个try块内,首先会经过这个块之后的catch块,如果被其中之一捕获,则执行完catch中的语句后跳出try-catch块继续执行程序;
- 如果未被处理或抛出的异常不在try块内,异常将会抛给其上层的调用者,同时抛出异常的函数立刻终止运行;
- 类似的程序逐层向上传递,如果
main函数依然不能捕获并处理异常,那么整个程序将会在此处中止。
函数可以在定义时于签名处声明它可能会抛出什么类型的异常,如:
1 | int divide(int a, int b) throw(int) {...} |
但是这种声明并不具备语法的强制力,更多是一种“告知”意义:即便函数抛出了声明范围外的异常,多数编译器也不会给出任何警告或报错。
标准异常类&自定义异常类
正如前面所看到的,catch块是基于抛出异常表达式的类型来监测和捕获异常的。因此想要区别不同种类的异常,最直观的方式就是定义一系列不同的异常类。C++中提供了许多标准的异常类,涵盖了一些常见的发生异常的原因。通过包含头文件<exception>,我们可以在程序中使用这些异常。
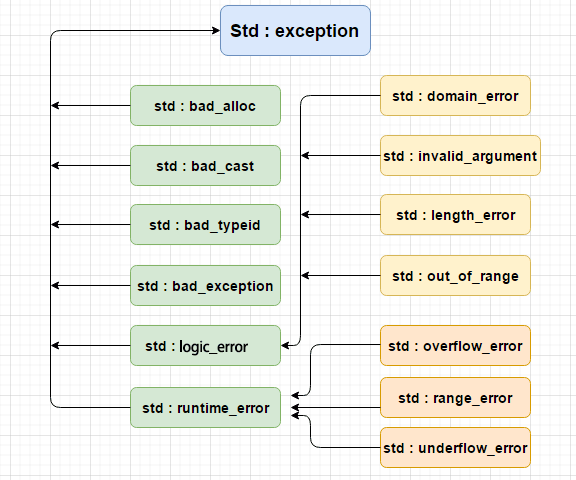
程序员还可以通过继承std::exception而自定义异常类,下面是一个例子:
1 |
|
这里what函数是exception类中定义的成员函数,可以返回一个字符串或指向字符串的指针代表错误信息。实际应用中也可重载和新定义其它的成员函数,包括构造函数、析构函数等。
Assert
Assert也可以被视为一种异常处理的方法,只不过机制十分简单粗暴:如果不满足Assert语句的条件,那么整个程序将会立即中止运行并输出错误信息。
1 |
|
虽然assert看上去是一个函数的形式,但实际上它只是一个宏。
命名空间与作用域
命名空间是C++新引入的一种作用域。关于它的一些具体知识和与其它作用域的关系,推荐参考这篇博文 。