C++ STL常用方法归纳
概述
STL(Standard Template Library,标准模板库)是C++提供的一个重要的组件,涵盖了一些常用的数据结构和容器,以及一些基础算法的封装形式。STL对于解决算法问题无疑是十分有力的工具,可以无需像C语言那样从头开始实现较为复杂的数据结构。STL的很多数据结构和算法形式上都能在Java中找到影子。
接下来的内容将分为三部分,第一部分以表格形式对比Vector, String, Set, Map四种容器,第二部分简单介绍Queue, Deque, Priority_queue和Pair四种模板,第三部分介绍一些封装的算法。
Vector, String, Set and Map
之所以将它们并列到一起,是因为这四种容器都是可以进行遍历的数据结构,可以使用Iterator作为迭代器,如Vector的迭代器就可以如下定义,其它容器的迭代器类似。
1 |
|
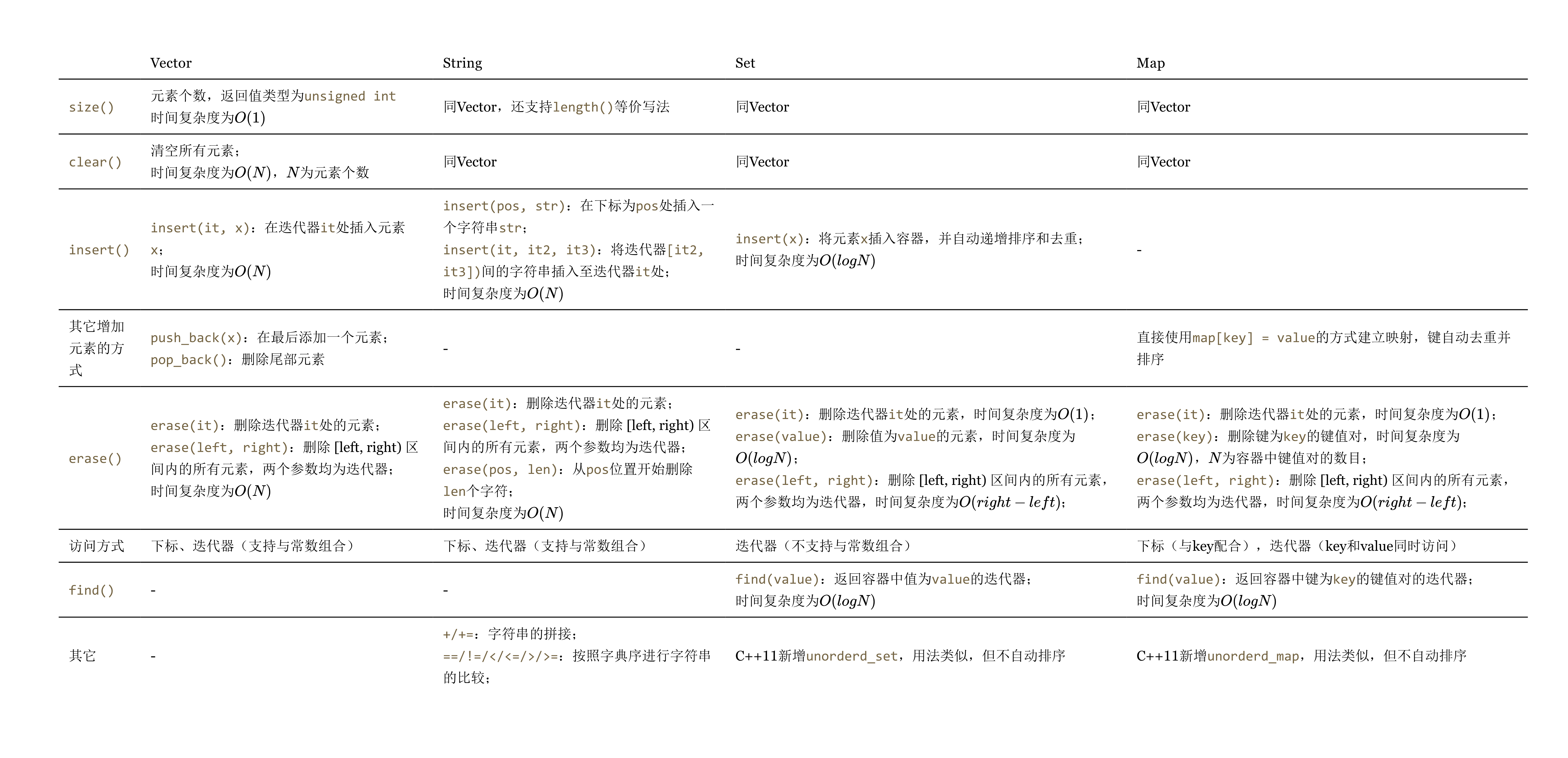
当然,四种同期也各有特点,比如Vector实现的是类似于变长数组的功能,String显然是字符串,Set是数学意义上的集合的实现,而Map则类似于python中的字典。我们将它们常用的一些方法列成下面的表格进行对比:
表格规模较大,如果视觉效果不佳,请在右下角设置按钮打开“阅读模式”查看,或者点击这里查看图片版。
| Vector | String | Set | Map | |
|---|---|---|---|---|
size() |
元素个数,返回值类型为unsigned int时间复杂度为 |
同Vector,还支持length()等价写法 |
同Vector | 同Vector |
clear() |
清空所有元素; 时间复杂度为,为元素个数 |
同Vector | 同Vector | 同Vector |
insert() |
insert(it, x):在迭代器it处插入元素x;时间复杂度为 |
insert(pos, str):在下标为pos处插入一个字符串str;insert(it, it2, it3):将迭代器[it2, it3])间的字符串插入至迭代器it处;时间复杂度为 |
insert(x):将元素x插入容器,并自动递增排序和去重;时间复杂度为 |
- |
| 其它增加元素的方式 | push_back(x):在最后添加一个元素;pop_back():删除尾部元素 |
- | - | 直接使用map[key] = value的方式建立映射,键自动去重并排序 |
erase() |
erase(it):删除迭代器it处的元素;erase(left, right):删除 [left, right) 区间内的所有元素,两个参数均为迭代器;时间复杂度为 |
erase(it):删除迭代器it处的元素;erase(left, right):删除 [left, right) 区间内的所有元素,两个参数均为迭代器;erase(pos, len):从pos位置开始删除len个字符;时间复杂度为 |
erase(it):删除迭代器it处的元素,时间复杂度为;erase(value):删除值为value的元素,时间复杂度为;erase(left, right):删除 [left, right) 区间内的所有元素,两个参数均为迭代器,时间复杂度为; |
erase(it):删除迭代器it处的元素,时间复杂度为;erase(key):删除键为key的键值对,时间复杂度为,为容器中键值对的数目;erase(left, right):删除 [left, right) 区间内的所有元素,两个参数均为迭代器,时间复杂度为; |
| 访问方式 | 下标、迭代器(支持与常数组合) | 下标、迭代器(支持与常数组合) | 迭代器(不支持与常数组合) | 下标(与key配合),迭代器(key和value同时访问) |
find() |
- | - | find(value):返回容器中值为value的迭代器;时间复杂度为 |
find(value):返回容器中键为key的键值对的迭代器;时间复杂度为 |
| 其它 | - | +/+=:字符串的拼接;==/!=/</<=/>/>=:按照字典序进行字符串的比较; |
C++11新增unorderd_set,用法类似,但不自动排序 |
C++11新增unorderd_map,用法类似,但不自动排序 |
Pair
简而言之,Pair就是两个任意类型数据的组合结构体。前面所述的Map在底层实现中用到了Pair,因此在使用Pair之前引用的头文件与Map相同。Pair的要点有三处:定义、访问、比较。
- 定义:使用
pair<type1, type2> p{val1, val2}初始化,或先定义再使用make_pair(val1, val2)赋值; - 访问:分别用
p.first和p.second访问第一个和第二个元素,也可以进行赋值; - 比较:可以像字符串那样使用比较运算符进行比较,依据是"先first后second"。
双端队列:Deque
Deque从字面意义上来讲是Queue的一种变体,但实际上其特性与Vector更加类似。Deque与Vector一点关键的不同是提供了在开头插入和删除元素的接口push_front(x)和pop_front(),并且这两个端口可以实现的时间复杂度。除此之外,Deque与Vector的各种接口基本都是一致的。
然而,在底层的实现原理上,Deque与Vector又大不一样。由于Deque分配的内存空间可能是不连续的,因此如果不是对两端元素进出有刚性需求,还是应当优先使用Vector,以提高遍历等操作的效率。
使用Deque之前需要在文件头部添加引用#include <deque>。
Queue, Priority_queue and Stack
这三种容器的特征与上面的四种有着较大的差异,而它们之间又有着较大的相似性,因此拿到一起来介绍。
顾名思义,Queue实现的是队列,Deque是双端队列,Priority_queue是用堆实现的优先队列,Stack是栈。队列和栈都是笔者大一数据结构课程的重点,也曾经用C手动实现过。从复杂度来讲,这些数据结构的功能相对也要简单一些,相似性也更大一些。
队列和栈的表格类比
这里我们列一个简单的“功能-接口”表来做比较。其中Deque由于较为复杂,将与Pair一起在后面单独介绍:
| 头文件 | 添加元素 | 弹出元素 | 访问边界元素 | 判空 | 元素个数 | |
|---|---|---|---|---|---|---|
| Queue Priority_queue Stack |
<queue><queue><stack> |
push(x) |
pop() |
front()&back()top()top() |
empty() |
size() |
Priority_queue优先级的设定
-
对于基本数据类型,默认使用数值降序/字典序来确定优先级。如果要颠倒顺序,应当采取下面的定义方式:
1
2
3
4
5
using namespace std;
priority_queue<int, vector<int>, less<int> > q; //默认的降序
priority_queue<int, vector<int>, greater<int> > q; //这将使队列将数值低的放在堆顶 -
对于结构体等自定义类型,要对"<"运算符进行重载或定义类似
qsort的cmp函数,来规定优先级。比如下面的代码就在结构体fruit内部规定以价格升序确定优先级:1
2
3
4
5
6
7
8
9
using namespace std;
struct fruit {
string name;
int price;
friend bool operator < (fruit f1, fruit f2) { //运算符重载函数
return f1.price > f2.price;
}
}另一种写法可以将重载函数单独拿出来,不依赖其它结构体而存在:
1
2
3
4
5
6
7
8
9
10
11
12
using namespace std;
struct fruit {
string name;
int price;
};
struct cmp {
bool operator () (fruit f1, fruit f2) { //运算符重载函数
return f1.price > f2.price;
}
};
priority_queue<fruit, vector<fruit>, cmp > q; //定义方式相应地进行调整
算法封装
这里简单介绍一下常用算法的封装形式和主要功能,不做太详细的阐述。使用这些算法之前,都需要在预处理部分加入头文件<algorithm>。
-
max(a, b)和min(a, b):在两个元素之间返回最大值或最小值; -
abs(x):返回整数x的绝对值; -
swap(a, b):交换参数a和b的值,无返回值; -
reverse(it1, it2):参数it1和it2可以是数组的指针或者STL容器的迭代器,这个函数将[it1,it2)范围内的元素进行翻转; -
fill(it1, it2, x):将数组或容器中[it1,it2)范围内元素均赋值x,x需与数组/容器本身数据类型对应; -
sort(it1, it2, [cmp]):将数组或容器中[it1,it2)范围内的元素进行排序,对于基本数据类型默认为升序,如果需要降序或使用自定义数据类型,需要提供cmp函数以确定排序规则。比如,对于一个结构体的二级排序可以这样写:1
2
3
4
5
6
7
8
9
10
11
using namespace std;
struct node {
int x, y;
}
bool cmp(node n1, node n2) {
if (n1.x != n2.x)
return n1.x > n2.x; //如果x属性不相等,则按照从大到小的顺序排列;
else
return n1.y < n2.y; //如果x属性相等,则按照y从小到大的顺序排列;
}
参考资料
- 《算法笔记》,胡凡、曾磊 主编,机械工业出版社(2016);
- C++ STL快速入门,C语言中文网,http://c.biancheng.net/stl/ 。STL中包含的容器和算法十分丰富,本篇笔记只是介绍了其中比较常用的一些。该网站中对于STL的功能有着更加详细的介绍。



{kind=link}